基于多模态大语言模型的遥感图像精准理解——动态分辨率与多尺度视觉-语言对齐研究
项目简介
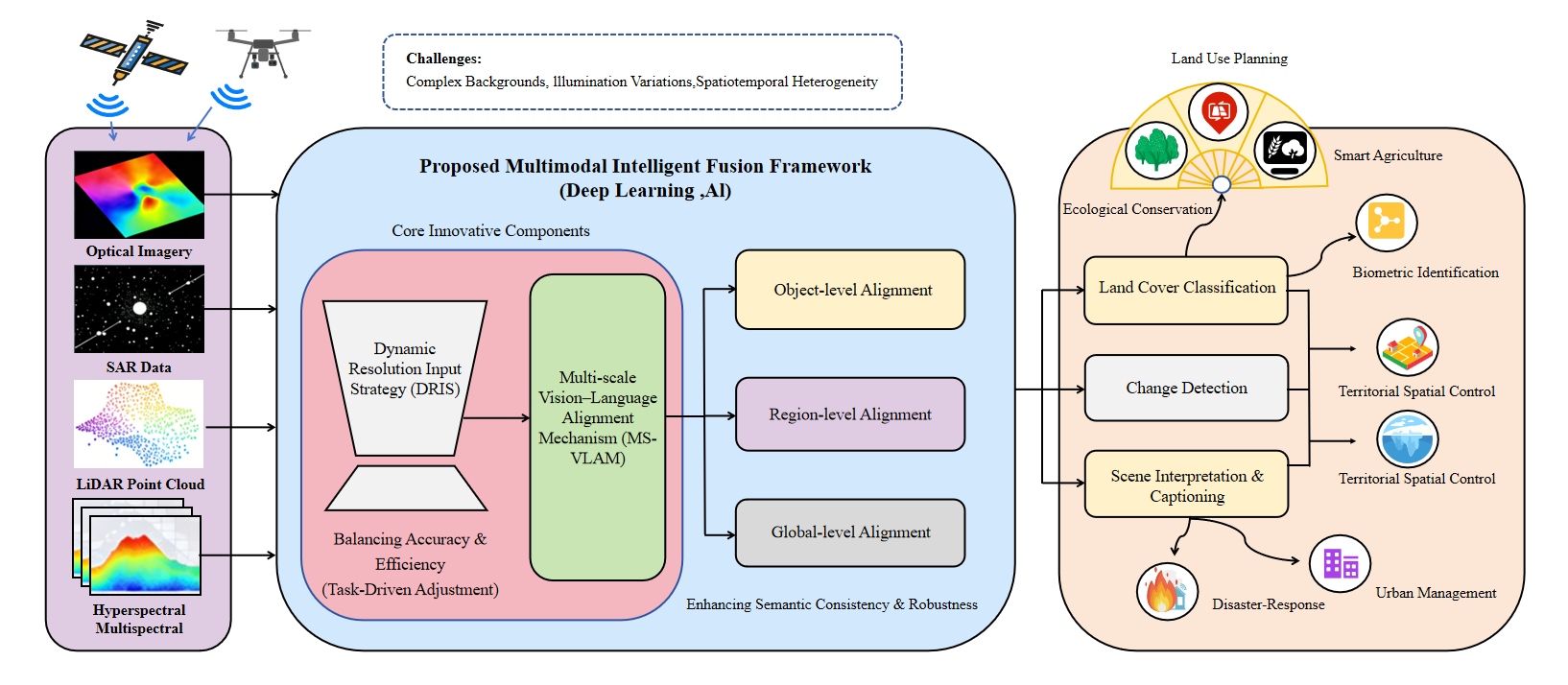
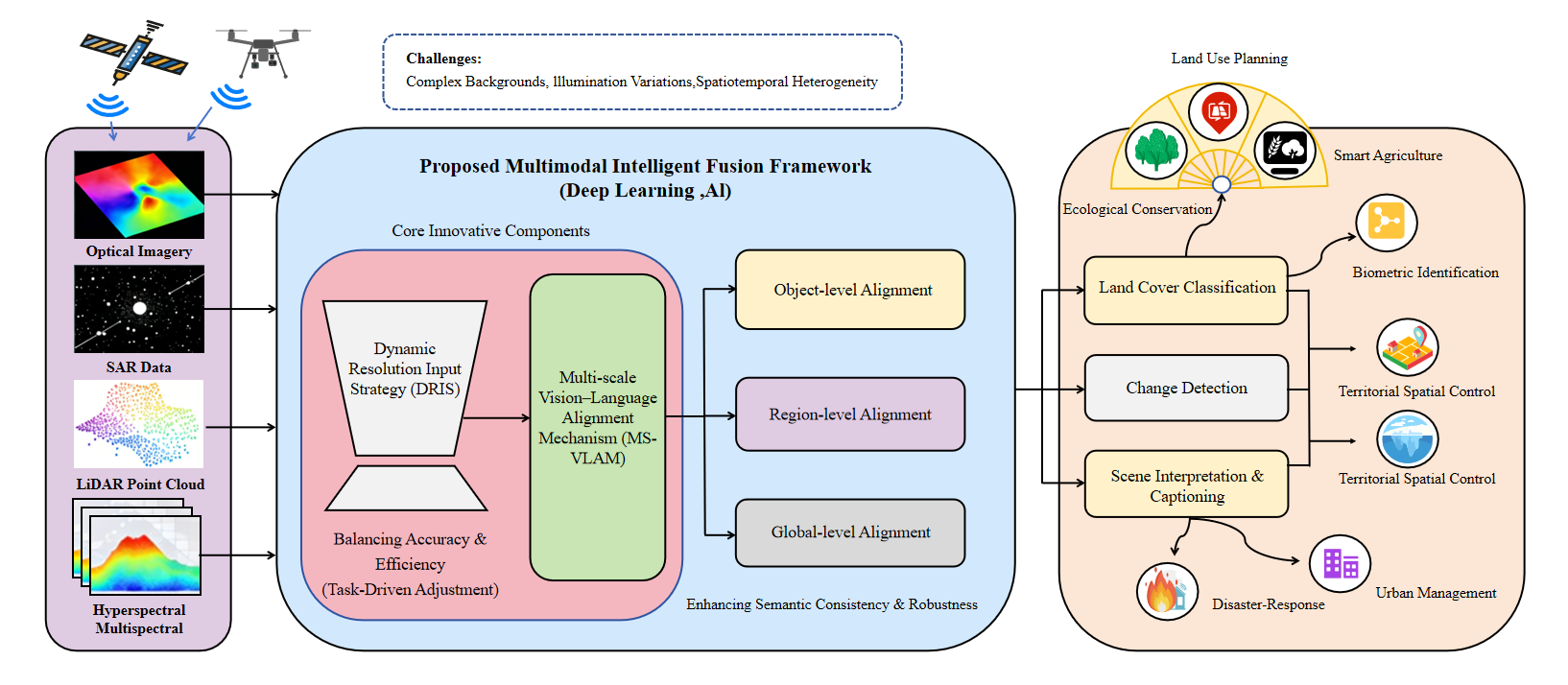
本项目是一项面向遥感场景的多模态视觉语言智能理解研究,旨在解决传统遥感模型在复杂场景下存在的尺度变化大、细粒度目标难识别以及跨模态语义对齐不足等问题。项目基于Vision-Language Model(VLM)构建了“分辨率自适应”与“分层语义对齐”的统一框架,提出动态分辨率输入策略(DRIS)与多尺度视觉语言对齐机制(MS-VLAM),实现了遥感图像与文本语义之间的高效跨模态理解与多层级语义建模。项目采用PyTorch、Transformer、CLIP等技术完成模型训练与优化,并在RSICD、NWPU-Captions、RS-GPT4V等多个遥感数据集上完成实验验证,在遥感图像描述、视觉定位与跨模态推理任务中取得了较优性能,具备良好的泛化能力与研究价值。
我的贡献
1. 负责项目整体技术方案设计与论文框架构建,提出“分辨率自适应 + 分层视觉语言对齐”的核心研究思路,完成方法总体架构设计与技术路线规划。 2. 负责核心算法模块设计与实现,提出动态分辨率输入策略(DRIS)与多尺度视觉语言对齐机制(MS-VLAM),完成多层级跨模态语义建模与分辨率自适应特征融合方法的构建。 3. 负责模型训练与实验验证工作,基于PyTorch搭建遥感视觉语言模型训练框架,完成RSICD、NWPU-Captions、RS-GPT4V等多个数据集的实验配置、参数调优、消融实验及性能分析。 4. 负责论文撰写与学术成果整理,完成Introduction、Method、Experiment等核心章节撰写,并独立设计DRIS、MS-VLAM等方法结构图与实验可视化图表。 5. 负责项目工程化与系统集成工作,完成多模态遥感数据处理流程、模型推理流程以及视觉语言联合训练模块的整合,实现从数据处理、模型训练到结果生成的完整研究流程。
成果亮点
模型在图像描述、视觉定位与跨模态推理任务上均显著优于现有最优方法,视觉定位精度达40.27%,跨模态推理总分6.574,同时计算效率大幅提升。 项目核心算法验证完成,相关论文在期刊返修中。